
Wie wir unsere Observability-Kosten durch Self-Hosting um 20x gesenkt haben
 Jonas Scholz
Jonas ScholzSliplane sitzt an einer ziemlich wichtigen Stelle im Stack unserer Kunden.
Wir sind ein PaaS. Wenn wir kaputt sind, ist ihre App vermutlich down. Wenn wir langsam sind, sind ihre Deployments langsam. Wenn unsere API einen 500 zurückgibt, ist das nicht nur ein lustiger kleiner Fehler in unseren Logs, sondern blockiert vielleicht jemanden beim shippen!
Das ist immer ernst, aber wird wichtiger, je mehr man wächst. Ein 1/100-Fehler wird plötzlich ein 10/100-Fehler und fällt deutlich mehr auf.
Zwischen Januar und Mai hat sich unsere User Activity mehr als verdreifacht. Über das letzte Jahr sind wir noch viel stärker gewachsen. Ich habe schon über einige Stack-Änderungen in Tech Stack Lessons from scaling 20x geschrieben, aber die größte operative Änderung seitdem war Observability.
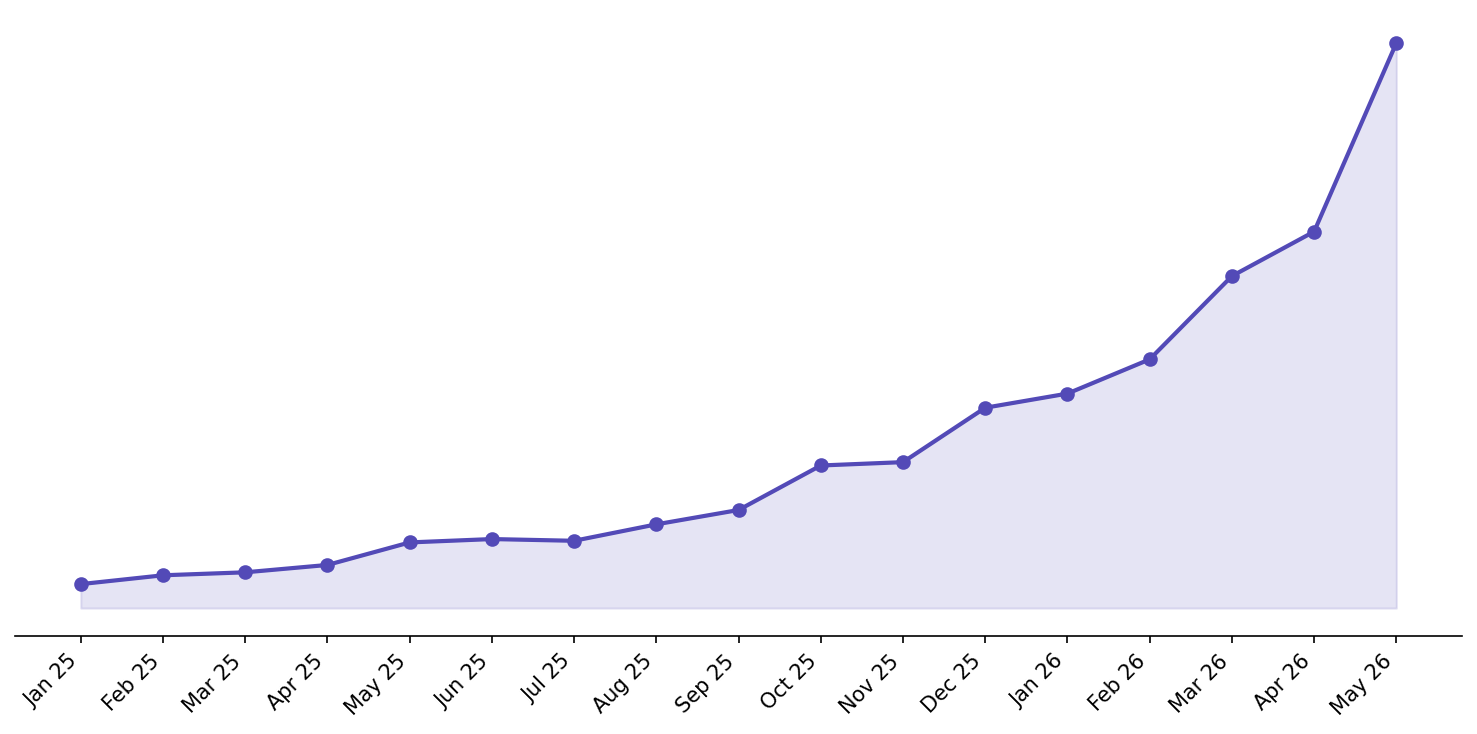
Also haben wir ungefähr im Januar angefangen, viel mehr in Observability zu investieren. Für uns hieß das vor allem drei Dinge:
- Metrics, die uns schnell sagen, wenn etwas komisch aussieht
- Traces, die zeigen, wo ein Request kaputtgegangen ist
- Logs für die Fälle, in denen Traces und Metrics nicht reichen
Traces wurden ziemlich schnell der wichtigste Teil. Zu wissen, dass ein API-Request mit einem 500 fehlgeschlagen ist, ist hilfreich. Viel hilfreicher ist aber zu wissen, welcher Downstream-Call kaputtgegangen ist, wie lange jeder Schritt gedauert hat und welcher Service den Fehler produziert hat. Sobald wir das für Requests über mehrere Systeme hinweg hatten, wurden viele Bugs deutlich leichter zu fixen.
Logs sind immer noch nützlich, aber sie sind nicht mehr das Erste, wonach wir greifen. Wenn Tracing gut funktioniert, sind Logs eher der Fallback als das Haupt-Debugging-Tool.
Das Problem: Observability wird schnell teuer
Der offensichtliche, aber nervige Teil ist: Je besser deine Observability wird, desto mehr Daten erzeugst du. Jeder zusätzliche Trace, Span, Metric, Log Line, Label und jedes Attribut macht Debugging angenehmer, erhöht aber auch die Datenmenge, die du aufnehmen, speichern und abfragen
Wir haben mit Axiom für Logs angefangen. Axiom ist ein gutes Produkt, aber unsere Kosten sind explodiert. Noch bevor wir richtig tief in Tracing und Metrics eingestiegen sind, waren wir schon bei ungefähr $1.000/Monat. Das war für uns keine Option :D.
Also sind wir zu Parseable gewechselt, einer Open-Source-Alternative zu Axiom. Am Anfang hat das funktioniert. Das Team war wirklich hilfreich, und ich schätze sehr, wie sehr sie uns beim Setup geholfen haben. Aber für unseren Use Case sind wir in Scaling-Probleme (?) gelaufen. Diese Issues zu debuggen war schwer, und die Performance war nicht da, wo wir sie gebraucht hätten. Das heißt nicht, dass Parseable schlecht ist. Es hat für uns einfach nicht gepasst.
Dann haben wir uns Grafana Cloud für das komplette Setup angeschaut, aber das Pricing hat für uns keinen Sinn ergeben. Basierend auf unserer aktuellen Loki-, Tempo- und Prometheus-Nutzung würde es ungefähr $25.000/Jahr kosten, all diese Daten in Grafana Cloud zu schicken.
Für ein größeres Unternehmen ist das wahrscheinlich okay. Für uns nicht.
Das Setup, bei dem wir gelandet sind
Also hosten wir jetzt die langweiligen Teile selbst:
- Loki für Logs
- Tempo für Traces
- Prometheus für Metrics
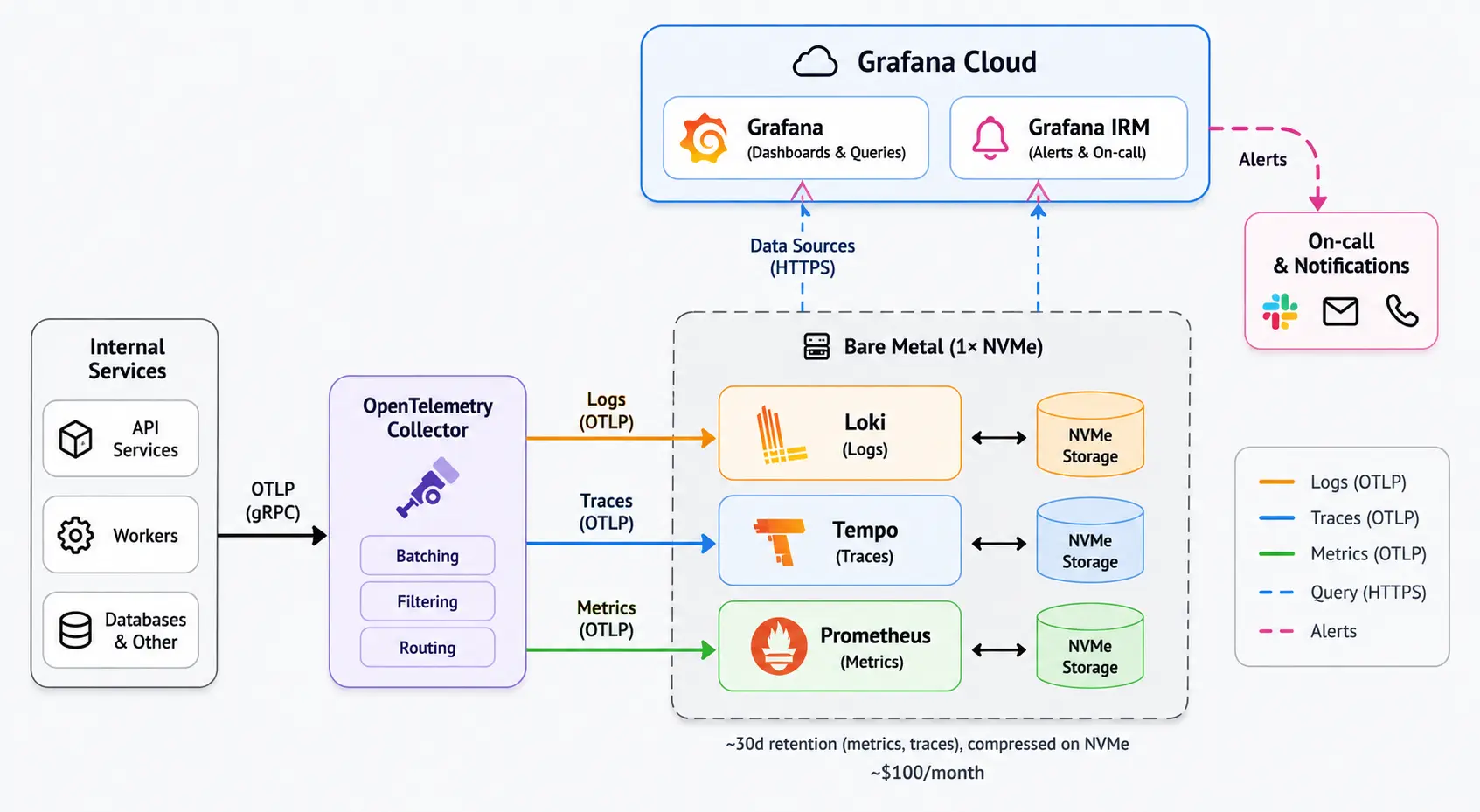
Wir nutzen Grafana Cloud weiterhin, aber nur für die Teile, bei denen es für uns wirklich Sinn ergibt. Grafana Cloud speichert unsere Observability-Daten nicht. Es verbindet sich nur mit unseren selbst gehosteten Data Sources und visualisiert sie. Dashboards, Panels, Queries, all das schöne Grafana-Zeug, ohne Hosted-Ingestion-Preise für jeden einzelnen Span und jede Log Line zu zahlen.
Wir nutzen außerdem Grafana IRM für On-Call-Schedules und Alerts, was super ist und genau die Art von Ding, die ich nicht selbst hosten will. Für Alert Routing, Escalation Policies und On-Call-Schedules zahle ich sehr gerne. Für Hosted-Ingestion-Preise auf jede interne Trace und Log Line eher weniger.
Die eigentlichen Daten liegen auf einer Bare-Metal-Machine mit NVMe-Disks. Kein Kubernetes-Cluster, kein Object-Storage-Backend, kein fancy Multi-Region-Observability-Lake. Nur Loki, Tempo, Prometheus, schnelle lokale Disks und genug Retention für das, was wir brauchen.
Die Collectors batchen die Daten, glätten die Ingestion ein bisschen und geben uns eine zentrale Stelle, an der wir steuern können, wohin Telemetry geht. Sobald die Services Traces standardisiert ausgeben, wird das Backend viel leichter austauschbar. Axiom, Parseable, Tempo, Grafana Cloud, irgendwas anderes später; die App-Instrumentation muss sich nicht so sehr darum kümmern.
Aktuell heißt das ungefähr 30 Tage Retention für Metrics und Traces. Storage war bisher kein Problem. Die Daten komprimieren extrem gut, und unser Scale ist nicht verrückt. Wir machen ein paar tausend Spans pro Sekunde, speichern ein paar Terabyte Logs und tracken ungefähr 200.000 Metrics. Das ist real genug, um relevant zu sein, aber nicht "wir brauchen ein dediziertes Observability-Team"-Scale.
Hosted Products werden an diesem Punkt schnell teuer. Eine einzelne NVMe-Box nicht. Unser aktuelles Setup kostet ungefähr $100/Monat.
Der Tradeoff
Natürlich ist das ein Tradeoff. Wenn die Machine stirbt, ist unsere interne Observability für eine Weile traurig (realistisch <15 Minuten, das Setup neu hochzuziehen ist lächerlich simpel und größtenteils automatisiert).
Wichtig ist: Das ist nur interne Observability. Dieses Setup speichert keine Customer Logs. Es speichert keine Customer Metrics. Es liegt nicht im kritischen Pfad von Customer Workloads. Es ist für unsere eigenen Traces, Metrics und Logs.
Wenn wir eine Stunde interne Traces verlieren, ist das ärgerlich. Aber es ist kein Customer-Data-Loss-Incident. Es ist auch nicht automatisch eine Production-Outage. Es heißt nur, dass wir für dieses Fenster weniger Sichtbarkeit haben, und das macht den Tradeoff deutlich einfacher.
Für eine Customer-facing Datenbank würde ich diese Entscheidung nicht treffen.
Der Vorteil ist, dass wir nicht mehr zögern, mehr Traces hinzuzufügen. Das ist wichtiger, als es klingt. Wenn jeder neue Span dich an deine SaaS-Rechnung denken lässt, sammelst du weniger Daten. Du samplest zu aggressiv. Du lässt nützliche Attribute weg. Du vermeidest Logs an Stellen, wo sie eigentlich helfen würden.
Würde ich das empfehlen?
Wie immer: kommt drauf an 🙃. Die Lektion hier ist nicht "jeder sollte Observability selbst hosten." Infrastruktur-Entscheidungen sind nur im Kontext gut oder schlecht.
Jede Stunde, die du damit verbringst, Observability-Infrastruktur zu betreiben, ist eine Stunde, die du nicht an deinem Produkt arbeitest. Wenn die Rechnung passt, zahl sie. Hosted Observability ist nützlich, weil sie dir eine Menge nervige Arbeit abnimmt.
Aber wenn die Rechnung dich davon abhält, die Daten zu sammeln, die du brauchst, wird Self-Hosting interessant. Die Grafana-Rechnung war nicht einfach nur "teuer." Das hätte unser Verhalten verändert. Wir hätten weniger Tracing, weniger Logs, weniger Metrics und weniger Kontext hinzugefügt.
Für uns ist das ein schlechter Deal. Wir müssen schnell debuggen. Wir müssen Fehler über Services hinweg verstehen. Wir müssen Regressionen sehen, bevor Kunden uns sagen, dass etwas kaputt ist.
Also haben wir die langweilige, pragmatische Entscheidung getroffen: Die Daten liegen auf einer günstigen Bare-Metal-Box, und Grafana Cloud behalten wir für den Teil, den wir wirklich von Grafana Cloud wollten: Visualisierung, Alerts und On-Call-Schedules.
Für uns haben ungefähr $25.000/Jahr für Hosted Observability keinen Sinn ergeben. Ungefähr $100/Monat für ein simples selbst gehostetes Setup schon. Wahrscheinlich haben wir die Availability ein bisschen reduziert, aber dafür haben wir unsere Fähigkeit verbessert, unseren Shit zu debuggen und eine bessere Plattform zu bauen. Diesen Tradeoff nehme ich jeden Tag :)
Wenn wir weiter wachsen, wird sich dieses Setup wieder ändern. Vielleicht fügen wir Object Storage hinzu, splitten Dinge über mehrere Server oder zahlen irgendwann doch für Hosted Observability, weil sich das Verhältnis von Geld zu Zeit ändert. Aber gerade gibt uns dieses Setup genau das, was wir brauchen: die Freiheit, mehr zu beobachten, nicht weniger, während wir versuchen, Sliplane nochmal 20x zu skalieren.
Cheers,
Jonas, Co-Founder sliplane.io