
Der Tech Stack eines Cloud Computing Startups: Lessons learned nach 20x Wachstum
 Jonas Scholz
Jonas ScholzVor einem Jahr habe ich über unseren Tech Stack geschrieben und wie er uns hilft, ein schlankes Cloud Computing Startup zu betreiben. Seitdem sind wir über 20x gewachsen. Das macht Spaß, aber bricht auch eine Menge Dinge und Annahmen; und zwingt einen, schnell harte Entscheidungen zu treffen
Hier ist, was sich geändert hat, was gleich geblieben ist, und was wir dabei gelernt haben.
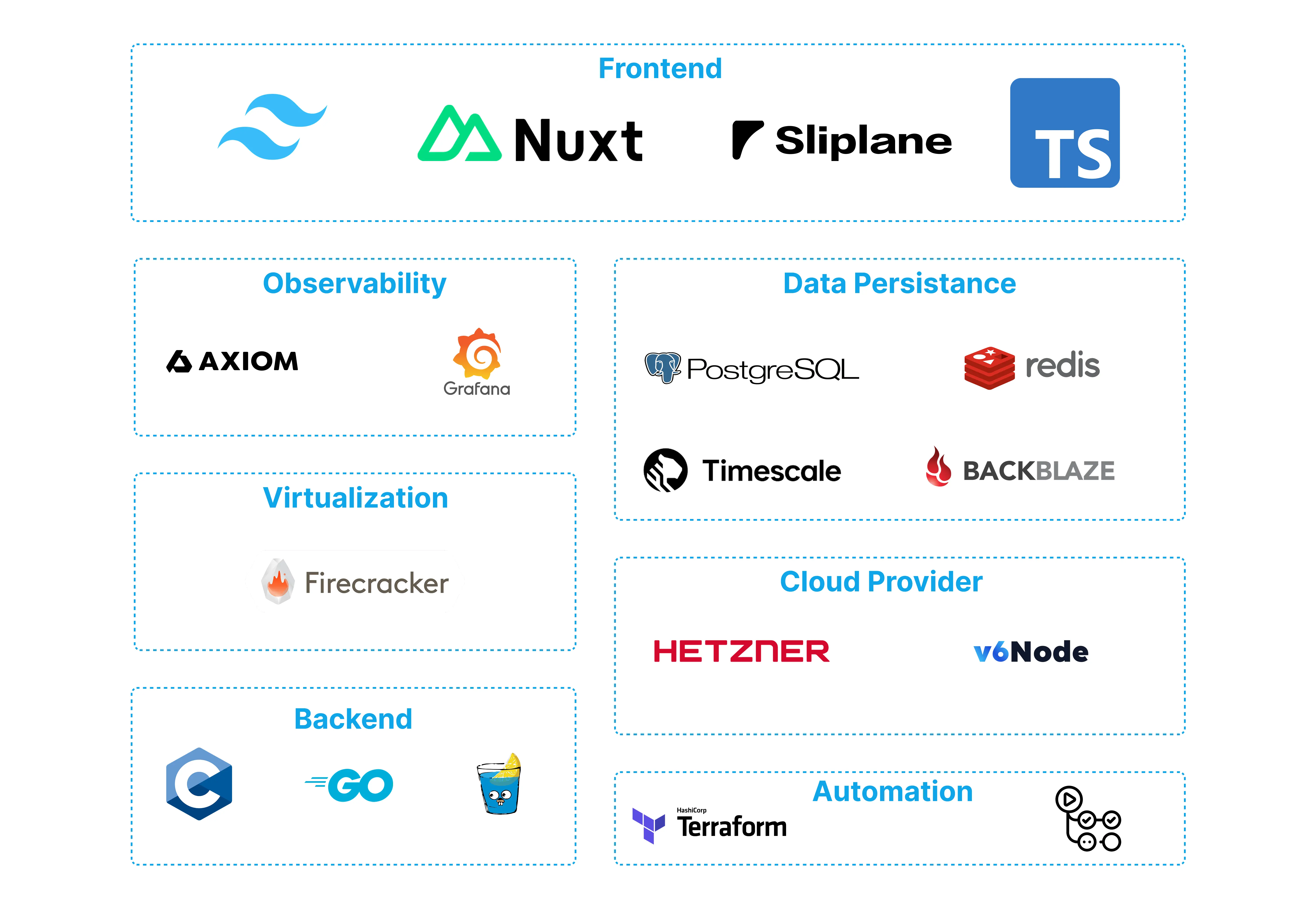
Was gleich geblieben ist
Manche Dinge funktionieren einfach. Unser Frontend ist immer noch Nuxt mit Typescript und Tailwind (RIP). Unser Backend ist immer noch Go mit Go-Gin. Wir laufen immer noch auf Hetzner Bare-Metal und nutzen Firecracker für Virtualisierung. Terraform verwaltet immer noch unsere Infrastruktur. Redis übernimmt weiterhin das Caching. Crisp betreibt unseren Kundensupport. AWS SES verschickt unsere transaktionalen E-Mails.
Was nicht kaputt ist, wird nicht repariert.
Aber einiges ist kaputtgegangen — oder wurde zu teuer, um es weiterzubetreiben.
Observability: Axiom → Parseable
Das war unsere größte operative Änderung. Letztes Jahr habe ich Axiom für Logs gelobt. Es war super, im Basis-Tarif. Bis wir skaliert haben.

Als unser Traffic wuchs, wuchs auch unser Bedarf an besserem Tracing und detaillierteren Logs. Unsere Axiom-Rechnung explodierte auf über 1.000€/Monat und stieg weiter. An dem Punkt muss man sich fragen: Ist das nachhaltig? Offensichtlich nicht lol.
Wir sind zu Parseable migriert, selbst gehostet auf Kubernetes mit Minio für S3-kompatiblen Storage, alles auf Bare-Metal. Das Produkt fühlt sich noch früh an, aber das Team ist nett und liefert schnell Fixes, wenn etwas kaputt ist. Großes Shoutout an Anant und Deba!
Würde ich es empfehlen? Wenn du nicht massenhaft Geld gegen Zeit tauschen kannst, ja. Observability selbst zu hosten ist Arbeit, aber bei unserer "Scale" (wir sind immer noch winzig) lohnt es sich. Wir nutzen weiterhin Grafana für Dashboards und Alerts, das hat sich nicht geändert (vorerst, die Rechnung fängt an wehzutun).
Object Storage: Backblaze → IONOS/Hetzner
Letztes Jahr haben wir Backblaze für Blob Storage genutzt. Es war günstig und zuverlässig. Das Problem war nicht technisch, es war rein politisch und eine Frage der Positionierung.
Als wir gewachsen sind, wuchs auch die Art der Kunden, die wir anziehen. Enterprise-Kunden, besonders europäische, haben angefangen, sich dagegen zu wehren, ihre Daten bei US-Anbietern zu speichern. DSGVO-Compliance, Datensouveränität, interne Richtlinien; die Gründe variierten, aber die Botschaft war klar. Keine US-Anbieter! Also begann unser Kreuzzug, alle US-Anbieter zu ersetzen, mit Backblaze.
Wir sind zu IONOS und Hetzner für Object Storage gewechselt. Sind sie so gut wie Backblaze? Nein, nicht mal annähernd. Aber sie sind europäisch, sie sind (gerade so) gut genug, und sie erfüllen die Anforderungen unserer Kunden. Ehrlich gesagt, wenn du nicht gezwungen bist sie zu nutzen, würde ich es nicht tun. Es fühlt sich an, als hätten wir hier keine echte Wahl.
CDN: Cloudflare → Bunny
Gleiche Geschichte wie beim Storage. Cloudflare ist ein unglaubliches Produkt mit Features, die wir nie nutzen werden. Aber Kunden haben nach einer europäischen Alternative gefragt.
Bunny passt perfekt. Es ist nicht so feature-complete wie Cloudflare, aber es erfüllt unsere CDN-Bedürfnisse perfekt. Es ist schnell, vernünftig bepreist und europäisch. In dem Fall war das nicht mal ein echter Tradeoff, Bunny macht genau das, was wir brauchen. Für unser super simples Setup hat die Migration weniger als 2 Stunden gedauert.
CI/CD: GitHub Actions → Namespace
GitHub Actions hat uns gut gedient, aber es stagniert. Wir brauchten Nested Virtualization, um Firecracker-Zeug zu testen. Wir brauchten bessere Performance. GitHub hat nicht geliefert.
Wir sind zu Namespace für unsere Runner gewechselt. Es ist ein tolles Produkt — auch europäisch, was hier zum Thema wird. Allein die Performance-Verbesserungen haben den Wechsel gerechtfertigt.
Allerdings werden wir wahrscheinlich bald zu komplett selbst gehosteten Runnern migrieren. Je mehr wir skalieren, desto mehr Kontrolle wollen wir.
Data Persistence: Das Große
Das war unsere bedeutendste architektonische Änderung. Letztes Jahr habe ich damit angegeben, alles in Postgres mit Timescale zu betreiben, inklusive Hunderten von Millionen Analytics-Rows. Das hat super funktioniert, bis unsere Datenbank 2TB erreicht hat.
Bei 2TB wird Postgres schwer zu managen. Dumme Queries können Prod runterreißen, Skalieren ist schmerzhaft. Datenbank-Profis werden mich hier auslachen, 2TB ist wahrscheinlich nichts im großen Schema der Dinge! Ich bin kein Postgres-Profi und hatte ehrlich gesagt nicht vor, einer zu werden. Außerdem haben die Kosten angefangen wehzutun. Besonders wenn man bedenkt, dass wir 2026 nochmal 20x machen wollen.
Also haben wir etwas Einfacheres gebaut: Frische Daten leben in Postgres, werden dann als Parquet-Dateien nach S3 geflusht. Für Queries nutzen wir DuckDB, um direkt von S3 zu lesen. DuckDB ist fantastisch.
Die Ergebnisse haben uns überrascht. P99-Latenz hat sich tatsächlich verbessert. Warum? Die meisten Queries sind "gib mir die Metriken der letzten 5 Minuten" oder "zeig mir die letzten 500 Logs." Das sind alles heiße Daten in Postgres. Historische Queries treffen S3, und DuckDB handhabt Parquet-Dateien wie ein Champion. Die sind, wenn nicht gecacht, natürlich etwas langsamer.
Diese Architektur spart Geld, skaliert besser und spielt unsere Stärken aus. Wir verstehen S3. Wir verstehen nicht, wie man ein 10TB Postgres-Cluster betreibt
Das Muster
Wenn ich auf all diese Änderungen zurückblicke, gibt es ein klares Muster:
- Alles europäisch. Kundendruck hat uns zu EU-Anbietern gedrängt. Nochmal, das ist keine technische Entscheidung. Es ist eine Business-Realität, wenn man über Startups und Indie-Hacker hinauswächst.
- Self-Host bei Scale. SaaS-Produkte sind super, bis deine Rechnung eine Schwelle überschreitet. Dann musst du rechnen, ob deine Zeit billiger ist als ihre Preise.
- Einfach schlägt clever. Wir haben keine fancy verteilte Datenbank gebaut. Wir flushen Daten nach S3 und querien sie mit DuckDB. Das ist nicht sexy, aber es funktioniert! (Eigentlich finde ich die Simplizität ziemlich sexy, aber nicht gut für Resume-Driven Development)
Was kommt als Nächstes
Wir werden wahrscheinlich bald unsere CI-Runner selbst hosten. Wir evaluieren Alternativen zu AWS SES, weil, du weißt schon, europäisch.
Der Stack wird sich weiter entwickeln. Das liegt in der Natur von Infrastruktur bei Scale. Aber die Kernphilosophie bleibt gleich: Halte es einfach, halte es wartbar, und füge nur Komplexität hinzu, wenn das Problem dich dazu zwingt.
Das ist, wo wir 2026 stehen. Zwanzigmal größer, ein paar harte Lektionen gelernt, und ein Stack, der europäischer ist als je zuvor.
Cheers,
Jonas