
Self-hosting von OpenWebUI mit Ollama - ganz einfach
 Jonas Scholz
Jonas ScholzOpenWebUI in Kombination mit Ollama bietet dir eine leistungsstarke ChatGPT-ähnliche Oberfläche mit lokalen Sprachmodellen - vollständig privat und unter deiner Kontrolle. Keine sensiblen Daten mehr an OpenAI senden oder pro Token bezahlen! In diesem Tutorial richten wir OpenWebUI mit Ollama auf Sliplane ein, ab nur 9 Euro pro Monat!
Warum OpenWebUI selbst hosten?
- Vollständige Privatsphäre: Deine Unterhaltungen verlassen niemals deinen Server
- Keine Nutzungslimits: Führe so viele Anfragen aus, wie dein Server verarbeiten kann
- Wähle deine Modelle: Nutze jedes Ollama-kompatible Modell (Llama, Mistral, Phi, etc.)
- Kosteneffizient: Feste 9€/Monat vs. Pay-per-Token Preismodell
- Volle Kontrolle: Anpassen und erweitern nach Bedarf
Einrichtung
- Registrierung bei sliplane.io, die Anmeldung ist kostenlos und du kannst dich mit deinem Github Account einloggen.
- Server erstellen: Wenn du dich gerade angemeldet hast, solltest du bereits einen Trial-Server haben, den du 48 Stunden lang kostenlos nutzen kannst. Falls nicht, gehe zu > Servers und klicke dann auf > Create Server
- Service erstellen: Gehe zu deinen Projekten (erstelle ein neues oder nutze das Standard-Projekt) und klicke auf > Deploy Service (oben rechts)
- Wähle das OpenWebUI Preset
- Klicke auf Deploy, warte bis der Service läuft und öffne dann die von Sliplane bereitgestellte Domain. Du findest diese in den Service-Einstellungen, sie sollte
service-name.sliplane.applauten - Ersten Account erstellen: Wenn du zum ersten Mal auf OpenWebUI zugreifst, wirst du aufgefordert, einen Admin-Account zu erstellen. Dies wird dein Hauptaccount mit vollen Admin-Rechten sein.
- Modell herunterladen:
- Gehe zu Admin Panel → Connections → Ollama
- Klicke auf das Download-Symbol
- Gib einen Modellnamen ein (z.B.
llama3.2für das neueste Llama-Modell) - Durchsuche verfügbare Modelle auf ollama.ai/library
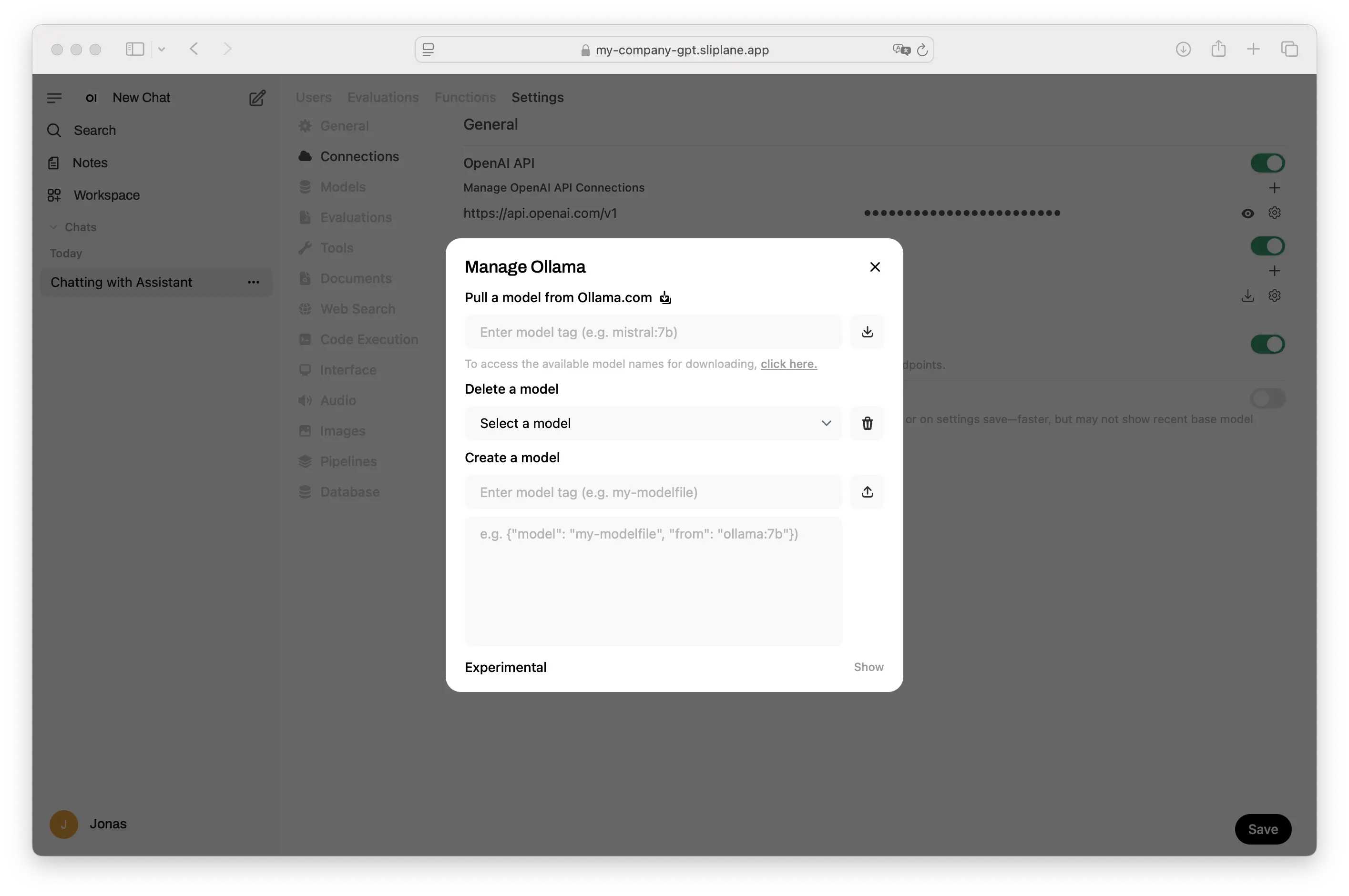
- Starte mit dem Chatten mit deiner privaten KI!
Den richtigen Server und das richtige Modell wählen
Der Server, den du wählst, hängt davon ab, ob du Modelle lokal ausführen oder externe APIs nutzen möchtest:
Externe APIs nutzen (9€/Monat)
Der Base Server (9€/Monat) ist perfekt, wenn du OpenWebUI mit externen API-Anbietern wie OpenAI, Anthropic oder Google nutzen möchtest. Obwohl dies nicht die vollen Privatsphäre-Vorteile lokaler Modelle bietet, erhältst du trotzdem eine bessere Oberfläche und Multi-User-Support für einen Bruchteil der Kosten von Team-Abonnements.
Lokale Modelle ausführen
Für echte Privatsphäre mit lokalen Modellen benötigst du leistungsstärkere Server:
| Server-Typ | Preis | RAM | Empfohlene Modelle | Anwendungsfall |
|---|---|---|---|---|
| Base | 9€ | 2GB | Nur externe APIs | OpenWebUI-Oberfläche mit Cloud-Anbietern |
| Dedicated Base | 49€ | 8GB | llama3.2:3b, mistral:7b | Kleine lokale Modelle, einfacher Chat |
| Dedicated Medium | 98€ | 16GB | llama3.2:7b, mixtral:8x7b | Mittlere Modelle, bessere Qualität |
| Dedicated Large | 196€ | 32GB | llama3.3:70b, qwen:32b | Große 20B+ Modelle, beste Leistung |
Warum Self-Hosting für viele die einzige Option ist
Für Unternehmen und Personen, die mit sensiblen Daten arbeiten, sind Cloud-KI-Services nicht nur teuer - sie sind oft gar keine Option:
- Compliance-Anforderungen: DSGVO, HIPAA und andere Vorschriften verbieten oft das Senden von Daten an US-basierte Services
- Das Patriot Act Problem: US-Cloud-Services sind gezwungen, Daten auf Anfrage an Behörden weiterzugeben
- Firmengeheimnisse: Viele Unternehmen können ihr geistiges Eigentum einfach nicht auf externen Servern riskieren
- Unbegrenzter Team-Zugang: Eine OpenWebUI-Instanz kann dein gesamtes Team bedienen ohne Pro-Nutzer-Preise
Kostenvergleich für Teams
| Service | 5 Nutzer | 10 Nutzer | 20 Nutzer | Privatsphäre | Compliance |
|---|---|---|---|---|---|
| ChatGPT Team | $150/Monat | $300/Monat | $600/Monat | ❌ US-Server | ❌ Patriot Act |
| Claude Team | $125/Monat | $250/Monat | $500/Monat | ❌ US-Server | ❌ Patriot Act |
| Self-hosted OpenWebUI | 9-196€/Monat | 9-196€/Monat | 9-196€/Monat | ✅ Deine Server | ✅ Volle Kontrolle |
Der wahre Wert liegt nicht nur in der Kostenersparnis - es geht darum, eine KI-Lösung zu haben, die du tatsächlich für sensible Arbeiten nutzen kannst.
FAQ
Welche Modelle kann ich nutzen?
Jedes Modell, das in der Ollama-Bibliothek verfügbar ist, einschließlich Llama, Mistral, Phi, Gemma und vielen mehr. Regelmäßig werden neue Modelle hinzugefügt.
Wie viel RAM brauche ich für verschiedene Modelle?
- 3B Parameter Modelle: ~4GB RAM (Dedicated Base minimum)
- 7B Parameter Modelle: ~8GB RAM (Dedicated Base minimum)
- 13B Parameter Modelle: ~16GB RAM (Dedicated Medium empfohlen)
- 20B+ Parameter Modelle: ~32GB RAM (Dedicated Large empfohlen)
Hinweis: Der 9€ Base Server kann keine lokalen Modelle ausführen. Nutze ihn mit externen API-Anbietern oder upgrade auf einen Dedicated Server für lokales Model-Hosting.
Kann ich mehrere Modelle nutzen?
Ja! Du kannst mehrere Modelle herunterladen und zwischen ihnen wechseln. OpenWebUI lässt dich für jede Unterhaltung auswählen, welches Modell du nutzen möchtest.
Ist es wirklich privat?
Ja! Die gesamte Verarbeitung findet auf deinem Server statt. Es werden keine Daten an externe APIs gesendet, es sei denn, du konfigurierst diese explizit.
Wie aktualisiere ich Modelle oder OpenWebUI?
Deploye den Service in Sliplane einfach neu, um die neueste Version zu erhalten. Für Modelle kannst du neue Versionen über die OpenWebUI-Oberfläche herunterladen.