
Self-hosting OpenWebUI with Ollama the easy way
 Jonas Scholz
Jonas ScholzOpenWebUI combined with Ollama gives you a powerful ChatGPT-like interface with local language models - completely private and under your control. No more sending sensitive data to OpenAI or paying per token! In this tutorial we're going to setup OpenWebUI with Ollama on sliplane, starting from just 9 euros per month!
Why self-host OpenWebUI?
- Complete privacy: Your conversations never leave your server
- No usage limits: Run as many queries as your server can handle
- Choose your models: Use any Ollama-compatible model (Llama, Mistral, Phi, etc.)
- Cost-effective: Fixed €9/month vs. pay-per-token pricing
- Full control: Customize and extend as needed
Setup
- Signup at sliplane.io, the signup is free and you can use your Github Account to login.
- Create a server: if you just signed up you should already have a trial server that you can use for 48 hours for free. If not, go to > Servers and then click > Create Server
- Create a service: go to your projects (create a new one or use the default one) and click > Deploy Service (top right)
- Select the OpenWebUI preset
- Click deploy, wait for the service to be up and then open the domain provided by sliplane. You can find that in the service settings, it should be
service-name.sliplane.app - Create your first account: When you first access OpenWebUI, you'll be prompted to create an admin account. This will be your main account with full admin privileges.
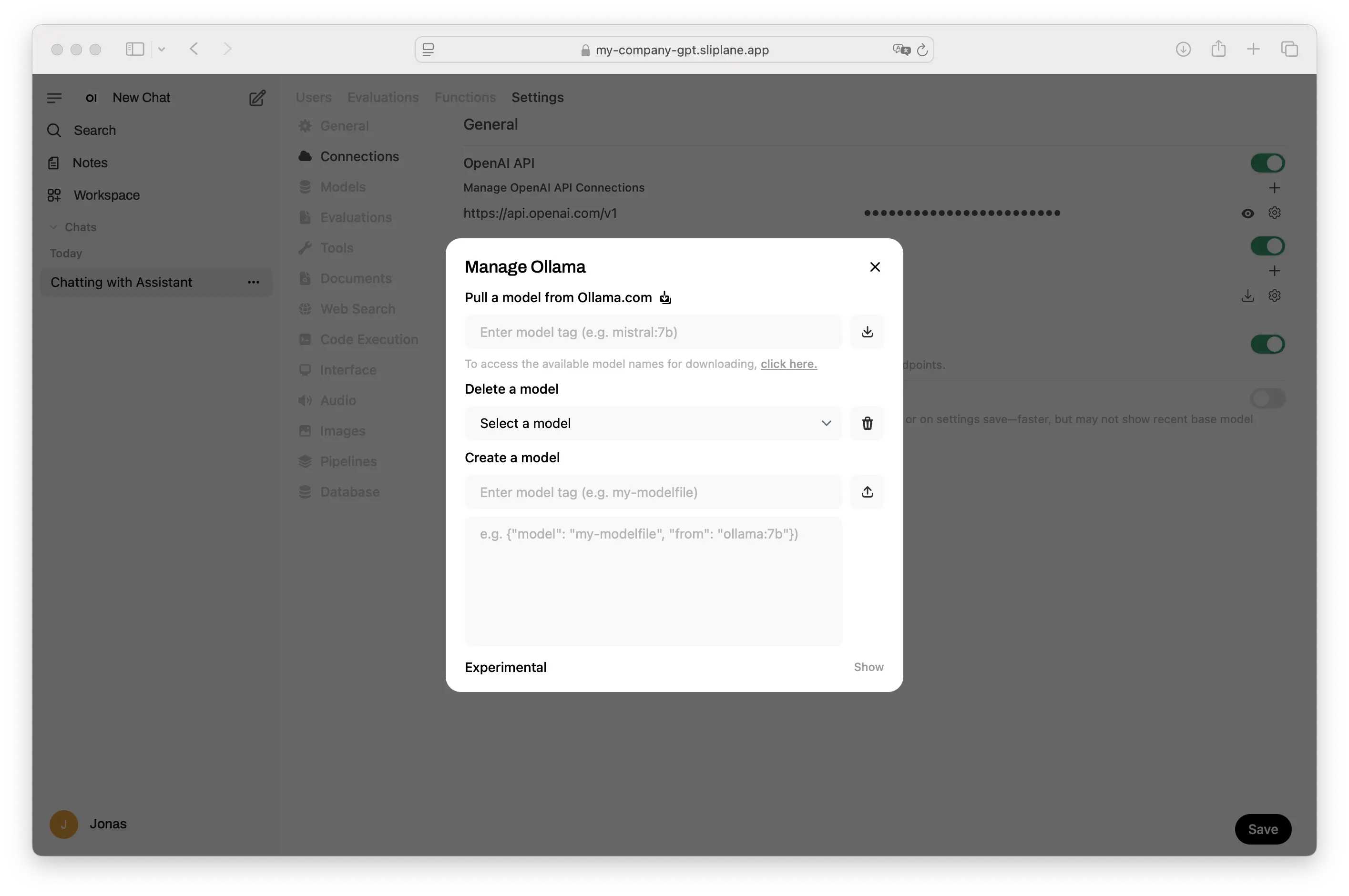
- Download a model:
- Go to Admin Panel → Connections → Ollama
- Click the download icon
- Enter a model name (e.g.,
llama3.2for the latest Llama model) - Browse available models at ollama.ai/library
- Start chatting with your private AI!
Choosing the right server and model
The server you choose depends on whether you want to run models locally or use external APIs:
Using External APIs (€9/month)
The Base server (€9/month) is perfect if you want to use OpenWebUI with external API providers like OpenAI, Anthropic, or Google. While this doesn't give you the full privacy benefits of local models, it still provides a better interface and multi-user support at a fraction of the cost of team subscriptions.
Running Local Models
For true privacy with local models, you'll need more powerful servers:
| Server Type | Price | RAM | Recommended Models | Use Case |
|---|---|---|---|---|
| Base | €9 | 2GB | External APIs only | OpenWebUI interface with cloud providers |
| Dedicated Base | €49 | 8GB | llama3.2:3b, mistral:7b | Small local models, basic chat |
| Dedicated Medium | €98 | 16GB | llama3.2:7b, mixtral:8x7b | Medium models, better quality |
| Dedicated Large | €196 | 32GB | llama3.3:70b, qwen:32b | Large 20B+ models, best performance |
Why self-hosting is the only option for many
For businesses and individuals who handle sensitive data, cloud AI services aren't just expensive - they're often not even an option:
- Compliance Requirements: GDPR, HIPAA, and other regulations often prohibit sending data to US-based services
- The Patriot Act Problem: US cloud services are forced to share data with authorities when requested
- Corporate Secrets: Many companies simply cannot risk their intellectual property on external servers
- Unlimited Team Access: One OpenWebUI instance can serve your entire team without per-seat pricing
Cost comparison for teams
| Service | 5 Users | 10 Users | 20 Users | Privacy | Compliance |
|---|---|---|---|---|---|
| ChatGPT Team | $150/month | $300/month | $600/month | ❌ US servers | ❌ Patriot Act |
| Claude Team | $125/month | $250/month | $500/month | ❌ US servers | ❌ Patriot Act |
| Self-hosted OpenWebUI | €9-196/month | €9-196/month | €9-196/month | ✅ Your servers | ✅ Full control |
The real value isn't just cost savings - it's having an AI solution you can actually use for sensitive work.
FAQ
What models can I use?
Any model available in the Ollama library, including Llama, Mistral, Phi, Gemma, and many more. New models are added regularly.
How much RAM do I need for different models?
- 3B parameter models: ~4GB RAM (Dedicated Base minimum)
- 7B parameter models: ~8GB RAM (Dedicated Base minimum)
- 13B parameter models: ~16GB RAM (Dedicated Medium recommended)
- 20B+ parameter models: ~32GB RAM (Dedicated Large recommended)
Note: The €9 Base server cannot run local models. Use it with external API providers or upgrade to a Dedicated server for local model hosting.
Can I use multiple models?
Yes! You can download and switch between multiple models. OpenWebUI lets you select which model to use for each conversation.
Is it really private?
Yes! All processing happens on your server. No data is sent to external APIs unless you explicitly configure them.
How do I update models or OpenWebUI?
Simply redeploy the service in Sliplane to get the latest version. For models, you can download new versions through the OpenWebUI interface.