
Tencent Hunyuan-A13B in 2026: Self-Hosting Notes and Limits
 Jonas Scholz
Jonas ScholzTencent just released a new open-source model called Hunyuan-A13B-Instruct. It has open weights (not sure about code), and it runs locally (well if you have a B200 GPU). If you're curious about how it performs and want to try it out yourself, here's how to set it up on a rented GPU in a few minutes.
2026 Current-State Summary
- Treat this as an experiment, not a cheap self-hosting recipe. The model is interesting, but the VRAM and download requirements put it in rented-GPU territory for most people.
- Use a GPU provider for inference tests. RunPod-style machines are a better fit than app platforms when the model needs roughly workstation-class or data-center GPU memory.
- Use Sliplane for the surrounding app. If you are building a chat UI, API gateway, queue worker, vector database, or admin app around a model endpoint, host those containers on Sliplane and call the GPU endpoint separately.
- Pin your runtime. GPU images, CUDA versions, and model code can drift quickly, so keep the exact image and dependency versions that worked for your test.
What is Hunyuan-A13B?
Hunyuan-A13B is a Mixture-of-Experts (MoE) model with 80 billion total parameters, but only 13 billion active at a time. This means inference is much cheaper than a full dense model.
Mixture-of-Experts (MoE) is a neural network architecture where only a subset of specialized "expert" sub-networks are activated for each input, reducing computation while increasing model capacity. A gating mechanism dynamically selects which experts to use based on the input, allowing the model to scale efficiently without always using all parameters.
Some highlights:
- Supports 256K context out of the box
- Fast and slow thinking modes
- Grouped Query Attention (GQA) for more efficient inference
- Agent-oriented tuning, with benchmark results on BFCL-v3 and τ-Bench
- Quantization support, including GPTQ
So far, it looks like a solid candidate for local experimentation, especially for long-context or agent-type tasks. I'm still testing how it compares to other models like LLaMA 3, Mixtral, and Claude 3.
Step 1: Spin Up a RunPod Instance
The easiest way to try it is RunPod(This link will give you between $5 and $500 credits!). You'll need:
- A 300 GB network volume
- A B200 GPU (I don't think less works, you need ~150GB of VRAM)
- A supported PyTorch image
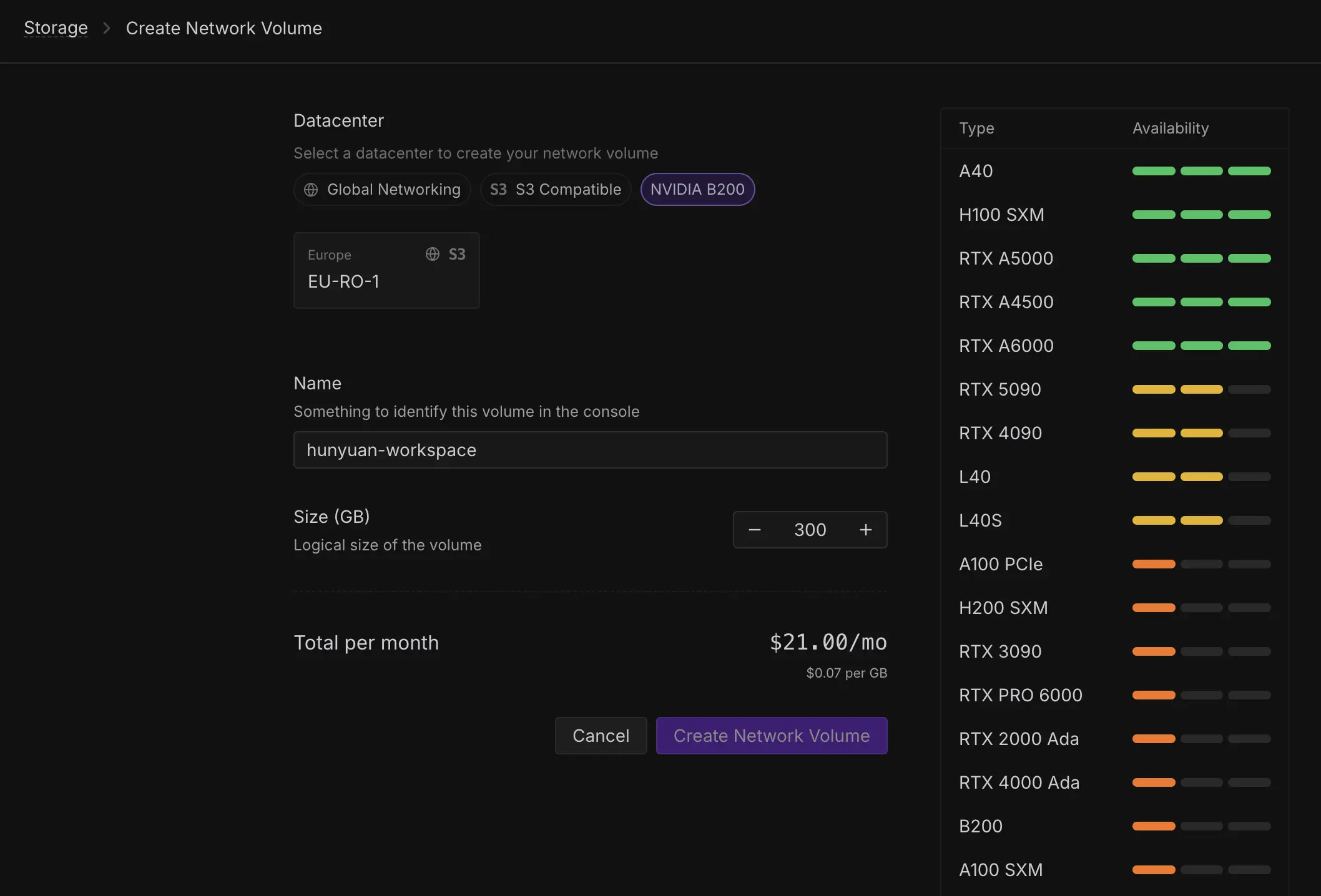
Create a Network Volume
- Region: use one where B200 is available (currently
eu-ro-1) - Size: 300 GB
- Cost: around $21/month (billed even if unused)
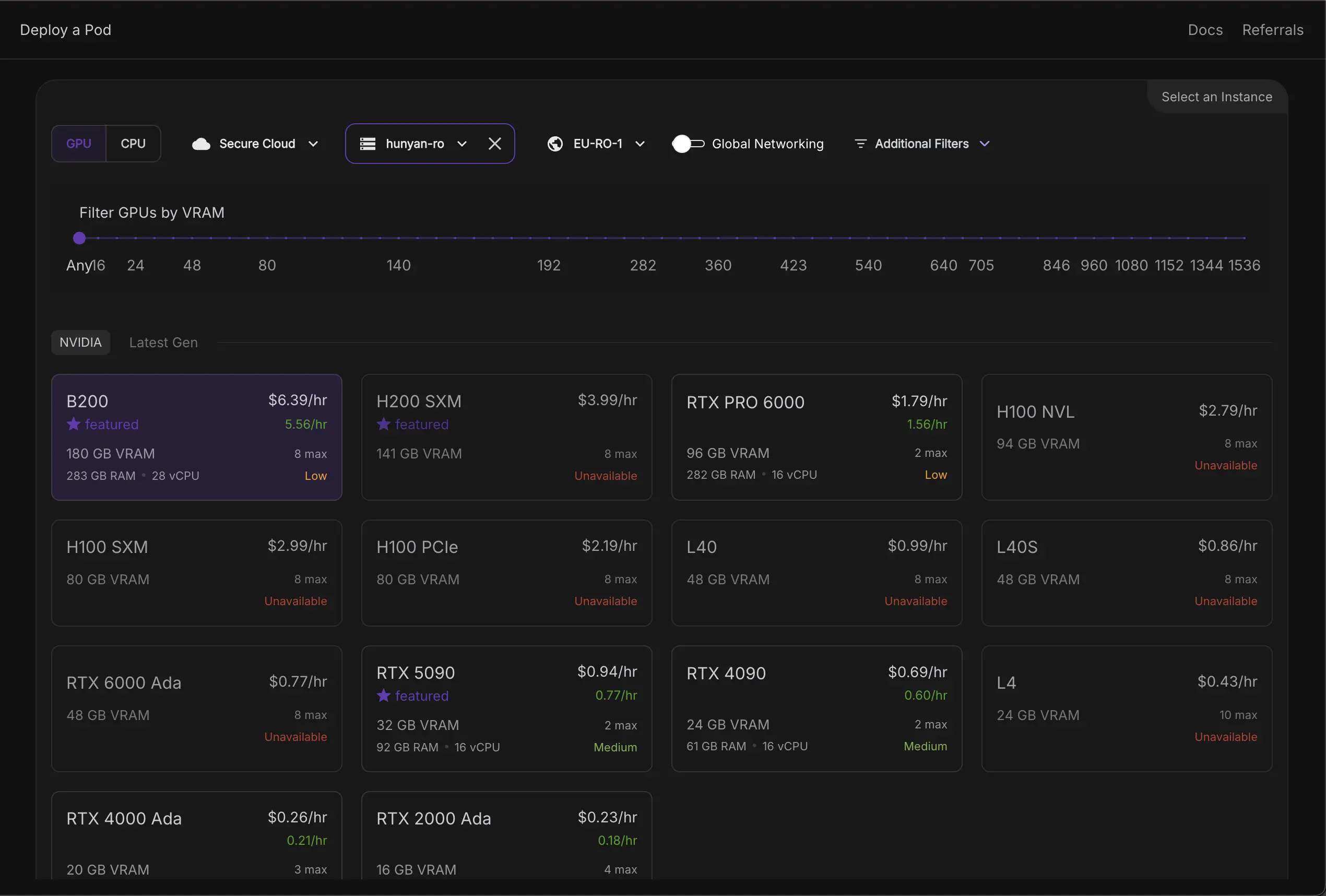
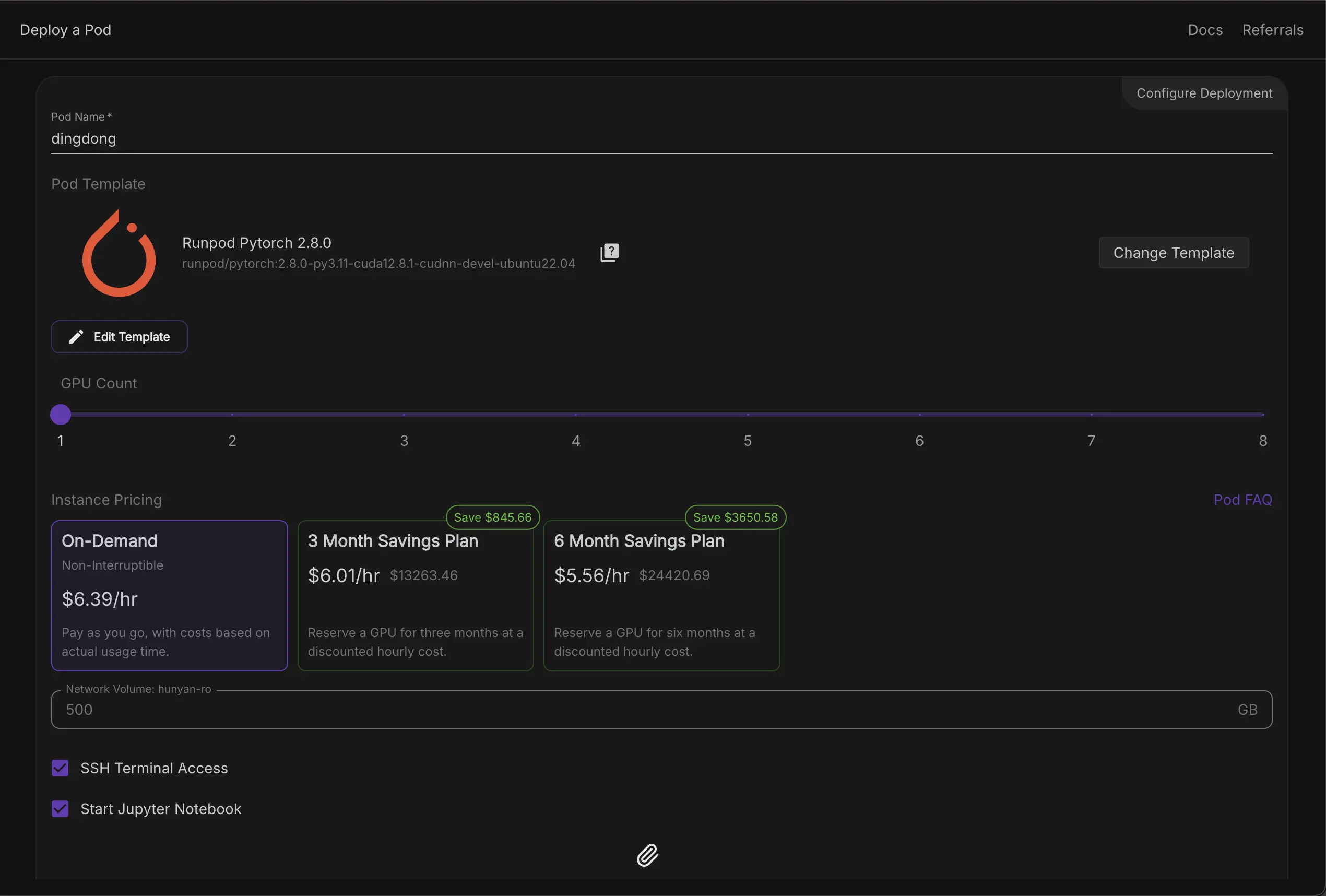
Create a Pod
- GPU type: B200
- Image:
runpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04⚠️ Earlier versions didn't work in my testing - GPU Count: 1
- Enable SSH + Jupyter
- Attach your network volume
Step 2: Install Dependencies
In the notebook terminal:
%pip install transformers tiktoken accelerate gptqmodel optimum
Step 3: Load the Model
Set the cache path so that downloads go to the mounted volume instead of the default root directory:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import os
import re
os.environ['HF_HOME'] = '/workspace/hf-cache' #
model_path = 'tencent/Hunyuan-A13B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_path, local_files_only=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, cache_dir='/workspace/hf-cache/', local_files_only=False, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
messages = [
{
"role": "user",
"content": "What does the frog say?"
},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, return_tensors="pt",
enable_thinking=True # Toggle thinking mode (default: True)
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=5000)
output_text = tokenizer.decode(outputs[0])
print(output_text)
Notes:
- First run will download ~150 GB of weights
- VRAM usage is ~153 GB during inference
- Loading into VRAM takes a few minutes
- If GPU util (not just VRAM) goes up, it's running
- You can set
device_map="cpu"if testing on CPU only. Make sure you have around 200GB of RAM and a good CPU
Costs
- B200 pod: $6.39/hour
- Network volume: $21/month, even if unused
- Suggestion: shut the pod down when not in use x)
Tooling Notes
llama.cppsupport is not there yet. PR in progress: #14425- Works fine in Python with
transformersandbfloat16
Benchmark
The official benchmarks are available on Hugging Face and evaluated by TRT-LLM-backend.
| Model | Hunyuan-Large | Qwen2.5-72B | Qwen3-A22B | Hunyuan-A13B |
|---|---|---|---|---|
| MMLU | 88.40 | 86.10 | 87.81 | 88.17 |
| MMLU-Pro | 60.20 | 58.10 | 68.18 | 67.23 |
| MMLU-Redux | 87.47 | 83.90 | 87.40 | 87.67 |
| BBH | 86.30 | 85.80 | 88.87 | 87.56 |
| SuperGPQA | 38.90 | 36.20 | 44.06 | 41.32 |
| EvalPlus | 75.69 | 65.93 | 77.60 | 78.64 |
| MultiPL-E | 59.13 | 60.50 | 65.94 | 69.33 |
| MBPP | 72.60 | 76.00 | 81.40 | 83.86 |
| CRUX-I | 57.00 | 57.63 | - | 70.13 |
| CRUX-O | 60.63 | 66.20 | 79.00 | 77.00 |
| MATH | 69.80 | 62.12 | 71.84 | 72.35 |
| CMATH | 91.30 | 84.80 | - | 91.17 |
| GSM8k | 92.80 | 91.50 | 94.39 | 91.83 |
| GPQA | 25.18 | 45.90 | 47.47 | 49.12 |
Hunyuan-A13B-Instruct has achieved highly competitive performance across multiple benchmarks, particularly in mathematics, science, agent domains, and more. We compared it with several powerful models, and the results are shown below. - Tencent
| Topic | Bench | OpenAI-o1-1217 | DeepSeek R1 | Qwen3-A22B | Hunyuan-A13B-Instruct |
|---|---|---|---|---|---|
| Mathematics | AIME 2024 AIME 2025 MATH | 74.3 79.2 96.4 | 79.8 70 94.9 | 85.7 81.5 94.0 | 87.3 76.8 94.3 |
| Science | GPQA-Diamond OlympiadBench | 78 83.1 | 71.5 82.4 | 71.1 85.7 | 71.2 82.7 |
| Coding | Livecodebench Fullstackbench ArtifactsBench | 63.9 64.6 38.6 | 65.9 71.6 44.6 | 70.7 65.6 44.6 | 63.9 67.8 43 |
| Reasoning | BBH DROP ZebraLogic | 80.4 90.2 81 | 83.7 92.2 78.7 | 88.9 90.3 80.3 | 89.1 91.1 84.7 |
| Instruction Following | IF-Eval SysBench | 91.8 82.5 | 88.3 77.7 | 83.4 74.2 | 84.7 76.1 |
| Text Creation | LengthCtrl InsCtrl | 60.1 74.8 | 55.9 69 | 53.3 73.7 | 55.4 71.9 |
| NLU | ComplexNLU Word-Task | 64.7 67.1 | 64.5 76.3 | 59.8 56.4 | 61.2 62.9 |
| Agent | BDCL v3 τ-Bench ComplexFuncBench C3-Bench | 67.8 60.4 47.6 58.8 | 56.9 43.8 41.1 55.3 | 70.8 44.6 40.6 51.7 | 78.3 54.7 61.2 63.5 |
What is Tencent 24113?
Tencent 24113 is not a separate model name in the official docs. If you landed here through that search term, it most likely points to Tencent's Hunyuan model family and this Hunyuan-A13B-Instruct release. The relevant model is Hunyuan-A13B-Instruct on Hugging Face, an open-weight MoE LLM with 80B total parameters and 13B active parameters during inference. That design matters because it gives you stronger benchmark performance than a small dense model while keeping inference cheaper than activating all 80B parameters. In practice, Tencent positions Hunyuan-A13B for long-context chat, agent workflows, coding, math, and research experiments where you want open weights and can rent enough GPU memory to run it.
Key benefits:
- 256K context support for long documents and agent memory
- Fast and slow thinking modes for different latency and reasoning needs
- MoE architecture with 13B active parameters for more efficient inference
- GPTQ and FP8 variants for more deployment options
- Official resources on GitHub and Hugging Face
Conclusion
This is one of the more interesting open MoE models out right now. It supports long contexts, has some thoughtful design choices, and it's easy enough to run. I'm still evaluating how good it actually is, especially compared to Mistral Magistral and other recent models. If you want to test it yourself, this setup gets you going quickly.
Cheers,
Jonas, Co-Founder of sliplane.io