Apache Tika mit OpenWebUI einrichten für besseres Document Parsing
 Jonas Scholz
Jonas ScholzWenn du schon mal versucht hast, das Standard-Dokumenten-Parsing von OpenWebUI zu nutzen – etwa ein PDF hochzuladen und Fragen dazu zu stellen – hast du wahrscheinlich gemerkt, dass es out of the box nicht besonders gut funktioniert. Lass uns das mit Apache Tika beheben.
Das Problem? OpenWebUI verwendet standardmäßig keine spezialisierten Tools zum Extrahieren von Text aus komplexen Dokumenten. Wenn deine Eingabe also ein gescanntes PDF, eine DOC-Datei oder auch nur ein seltsam formatiertes PDF ist, wird es wahrscheinlich fehlschlagen oder unlesbaren Output produzieren.
Hier ist ein 1-minütiges Tutorial, wie du Apache Tika mit OpenWebUI einrichtest:
Warum Apache Tika verwenden?
Apache Tika ist ein ausgereiftes Open-Source-Projekt der Apache Foundation. Es existiert seit über 18 Jahren und verarbeitet hunderte von Dokumentformaten, darunter:
- DOC/DOCX
- PPT/PPTX
- XLS/XLSX
- EPUB
- HTML
- Plaintext
- Legacy-Formate wie DOC (97-2003)
- Viele mehr
Tika extrahiert Text und Metadaten zuverlässig und ist damit ein viel besseres Backend für das Dokumenten-Parsing in OpenWebUI.
Wie du Apache Tika mit OpenWebUI einrichtest
Docker Compose Setup
Hier ist eine einfache compose.yml Datei, die sowohl OpenWebUI als auch Apache Tika ausführt:
services:
openwebui:
image: ghcr.io/open-webui/open-webui:main
ports:
- "3000:8080"
volumes:
- openwebui:/app/backend/data
tika:
image: apache/tika:latest
ports:
- "9998:9998"
volumes:
openwebui:
OpenWebUI konfigurieren
- Starte beide Services mit
docker compose up -d - Öffne OpenWebUI unter
http://localhost:3000 - Gehe zu Admin Panel → Settings → Documents
- Setze die Content Extraction Engine auf Tika und dann die URL auf:
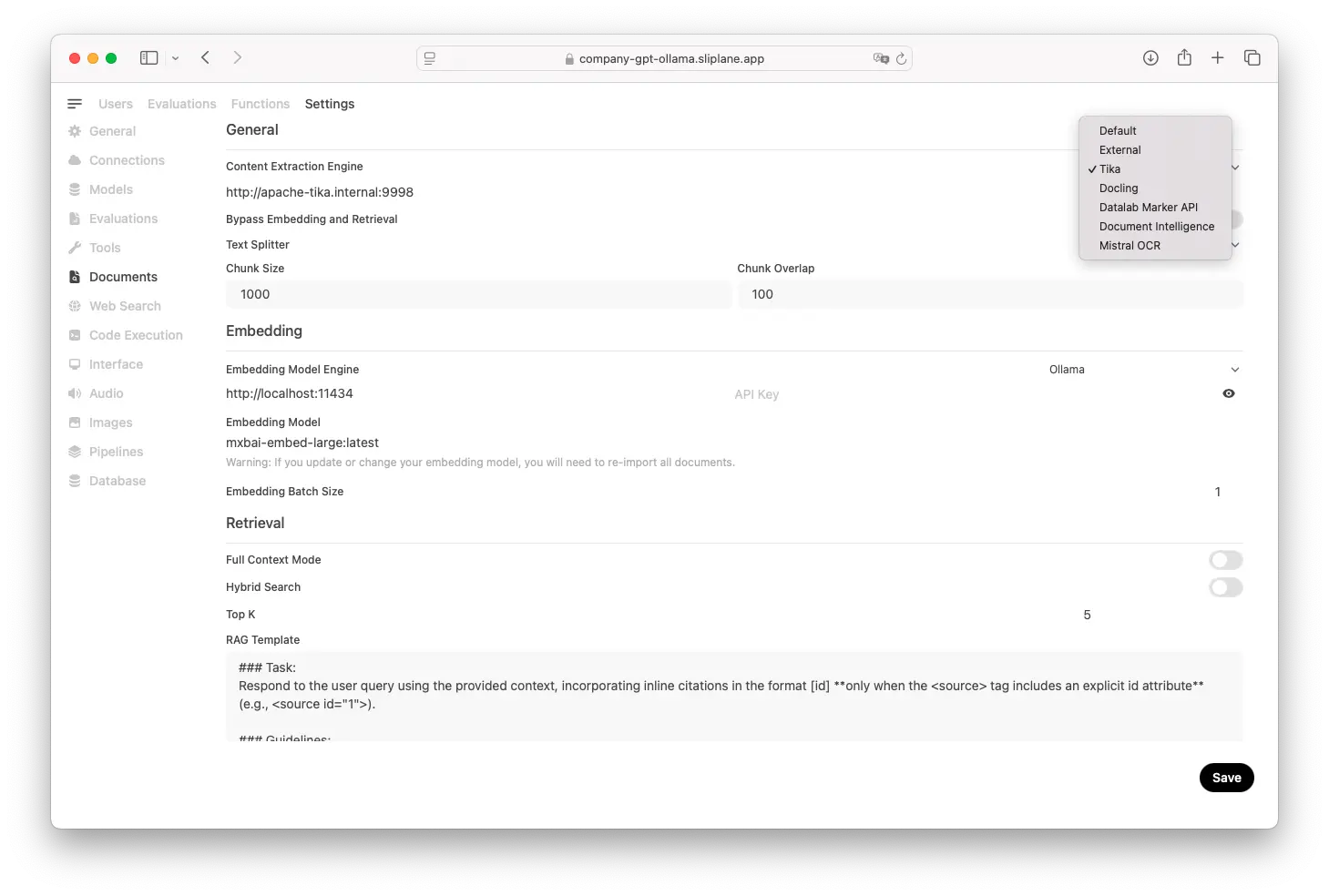
http://tika:9998/tika
- Speichere die Einstellungen
- Validiere das Setup, indem du ein Dokument hochlädst und die Tika-Logs überprüfst.
Du solltest etwas wie das hier sehen:
INFO [qtp1393198164-60] 15:03:46,042 org.apache.tika.server.core.resource.TikaResource /tika (application/pdf)
Beispiel: Ein PDF parsen
Lade ein PDF in OpenWebUI hoch, stelle Fragen zum Inhalt und vergleiche die Ergebnisse vor und nach der Einrichtung von Tika. Du wirst merken:
- Bessere Textextraktion
- Unterstützung für mehr Formate
- Weniger Parsing-Fehler
Probiere komplexe Dokumente aus wie:
- Gescannte PDFs
- Mehrspaltige Layouts
- Dokumente mit Tabellen
- Legacy Microsoft Office Dateien
Fehlerbehebung
Wenn Dokumente nicht korrekt geparst werden:
- Prüfe ob Tika läuft:
docker ps | grep tika - Teste Tika direkt:
curl -X PUT --data-binary @dein-dokument.pdf http://localhost:9998/tika --header "Content-type: application/pdf" - Prüfe OpenWebUI Logs:
docker logs <openwebui-container-id>
FAQ
Gibt es eine Alternative zu Apache Tika? Ja, aber die meisten Alternativen sind entweder kommerziell oder eingeschränkter. Tika ist kostenlos, Open Source und extrem bewährt.
Kostet das etwas? Nein. Sowohl OpenWebUI als auch Apache Tika sind Open Source und kostenlos nutzbar.
Skaliert es? Für die meisten Anwendungsfälle reicht ein einzelner Tika Container. Wenn du skalieren musst, kannst du mehrere Tika Container hinter einem Load Balancer betreiben.
Was ist mit Sicherheit? Tika verarbeitet Dokumente serverseitig, stelle also sicher, dass dein Setup ordentlich abgesichert ist, wenn du sensible Dokumente verarbeitest. Erwäge den Betrieb in einer isolierten Umgebung.
Video Demo
Hier ist ein 40-Sekunden Demo Video, das zeigt:
- Wie du Apache Tika auf Sliplane deployst
- Wie du es in OpenWebUI konfigurierst
- Wie du es mit einem echten PDF testest
Fazit
Die Einrichtung von Apache Tika mit OpenWebUI verwandelt das Dokumenten-Parsing von frustrierend zu funktional. Mit nur wenigen Konfigurationsschritten kannst du hunderte von Dokumentformaten zuverlässig verarbeiten.
Wenn du Fragen hast, melde dich gerne in unserem Support-Chat (unten rechts).
Cheers, Jonas